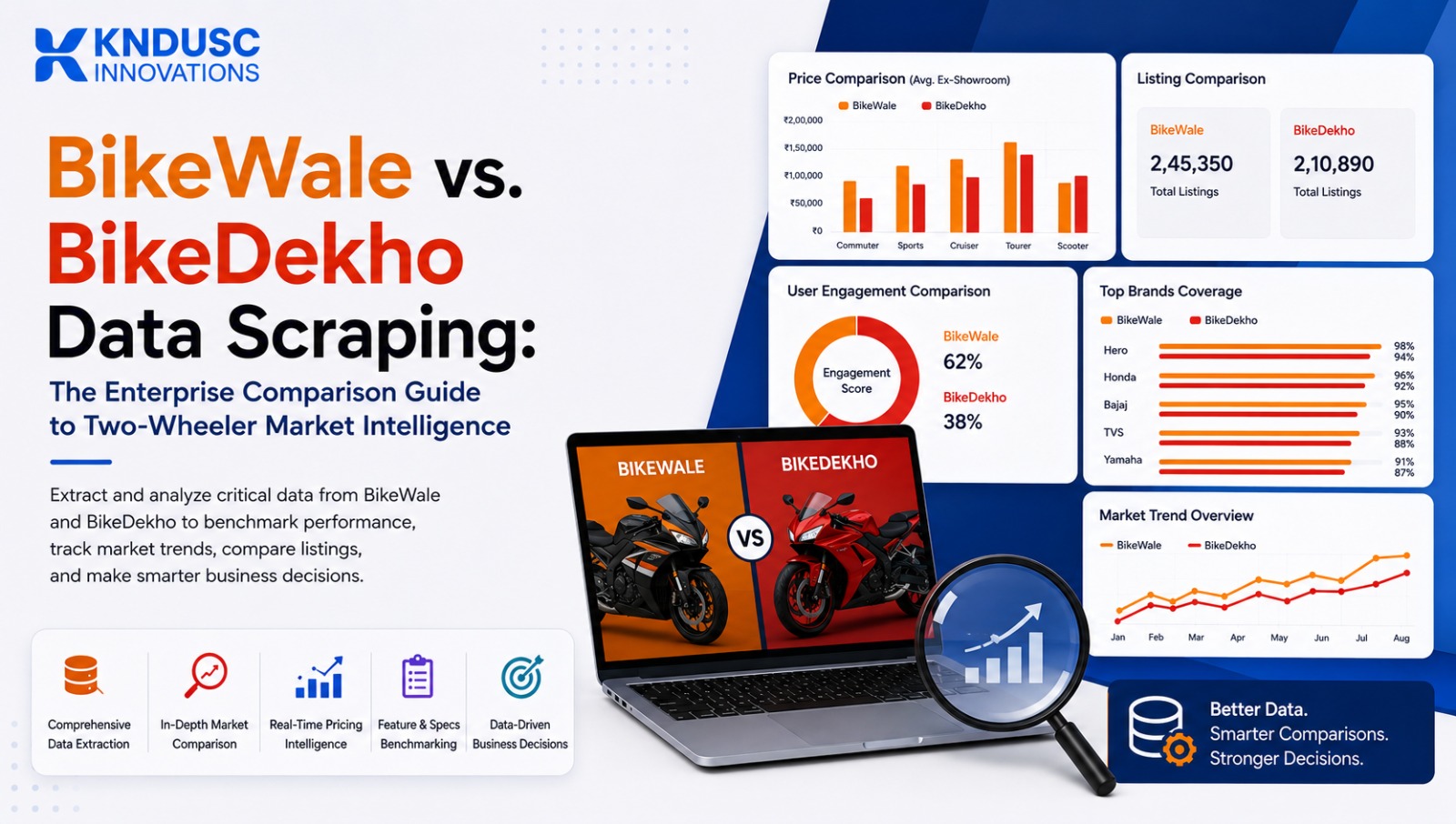
India stands as the world’s absolute largest two-wheeler market. Driven by a massive surge in EV commuter options and a rapidly growing premium performance motorcycle segment, the digital ecosystem tracking this industry has become incredibly high-value. At the center of this auto tech intelligence sector are India’s two leading aggregation giants: BikeWale and BikeDekho.
For original equipment manufacturers (OEMs), dealership networks, auto-fintech lenders, and insurance underwriters, having real-time access to these platforms' public data is a massive operational asset.
- What are the exact, city-level regional variations in on-road prices across tier-2 and tier-3 markets?
- How quickly are upcoming EV scooter variants gaining user-review traction compared to legacy internal combustion engines?
- What are the current depreciation benchmarks for used vehicle inventories across competing multi-brand dealerships?
Extracting this information at scale means dealing with highly complex web layouts and strict anti-bot firewalls. In this detailed guide, we map out a technical data-scraping comparison between BikeWale and BikeDekho, exposing where key data points live and outlining how KNDUSC Innovations converts raw automotive web pages into clean, actionable enterprise data feeds.
1. Structural Comparison: Data Architecture Profiles
While both portals aim to help Indian consumers research, compare, and finance two-wheelers, their underlying frontend architectures store and display data in fundamentally distinct patterns.
[Target: BikeWale Engine] ──> Structured HTML Layout ──> Extraction via Direct CSS/XPath Selectors
[Target: BikeDekho Engine] ──> Hydrated React DOM Layout ──> Extraction via Nested JSON Client States
BikeWale: The Traditional, High-Density Directory
BikeWale relies heavily on a highly categorized, clean directory structure. Variant details (such as Drum vs. Disc brakes or alloy wheel configurations) are laid out directly within highly semantic HTML components. For web crawlers, this clean layout simplifies structural XPath or CSS selector mapping, making broad, platform-wide catalogue scrapes incredibly fast and resource-efficient.
BikeDekho: The Dynamic, Asynchronous SPA
BikeDekho runs on a highly modern Single Page Application (SPA) architecture driven by hydrated JavaScript states. Rather than printing key variables cleanly within static HTML text blocks, its layout injects prices, calculated EMI breakdowns, and regional dealership lists dynamically via client-side scripts. Capturing this data requires scrapers capable of executing JavaScript seamlessly or identifying and extracting data straight from nested backend JSON payloads.
2. Critical Automotive Data Layers: Mapping the Extractions
A production-grade two-wheeler data scraping pipeline targets specific high-yield metrics across both platforms to feed predictive analytics models:
| Target Domain | BikeWale Data Layout | BikeDekho Data Layout | Operational Value for Businesses |
|---|---|---|---|
| On-Road Pricing Elements | Explicit breakdowns of Ex-Showroom, RTO fees, and local insurance estimates by city. | Algorithmic "Check On-Road Price" queries that require entering a localized zip code or city. | Powers hyper-local pricing engines for competing dealerships and localized consumer offers. |
| Fintech & EMI Calculations | Fixed down-payment interest sliders displayed transparently on product variant tables. | Dynamic multi-bank quote matrices tied directly to real-time credit inquiries. | Helps fintech lenders assess competitive interest rates and loan-to-value (LTV) limits. |
| Used Vehicle Valuations | Aggregated classified listings categorized by owner history, usage mileage, and location. | Algorithmic second-hand evaluation calculators driven by real-time seller inputs. | Establishes precise vehicle depreciation curves for used inventory management. |
| User Sentiment Analytics | Verified owner reviews detailing real-world fuel economy and long-term maintenance costs. | High-volume star-rating sets parsed across individual feature sets (e.g., performance, comfort). | Provides R&D teams and auto OEMs with immediate feedback on vehicle performance. |
3. Technical Obstacles: Bypassing Advanced Auto-Tech Security
As two of India's most highly trafficked automotive web assets, both platforms employ strict, multi-layered anti-scraping defenses to protect their proprietary pricing databases and dealer contact lists.
Regional Geo-Fencing & Localization Blocks
Both platforms adjust their inventories and prices depending on the user’s selected Indian metro or region. A web scraper utilizing a generic cloud hosting IP address will often find itself locked to a default national showroom page or blocked entirely. Passing through requires deploying a robust network of premium proxies strategically located across Indian metropolitan hubs (such as Mumbai, Delhi, Bengaluru, and Chennai) to ensure the scraper extracts correct regional ex-showroom and on-road price sets.
Behavioral Analysis and CAPTCHA Injection
When a script makes rapid, high-volume requests across deep model links, edge firewalls trigger aggressive behavioral checks. Instead of serving clean data, the connection is instantly met with complex image CAPTCHAs or immediate IP bans. Bypassing these filters requires using customized headless automation tools (like Playwright or Puppeteer) configured to introduce human-like browsing speeds, non-linear cursor scrolling, and random intervals between requests.
4. Turning Raw Auto Code into High-Fidelity Data Assets
Raw text outputs scraped from deep auto-portal listings are naturally messy. Bike models might be spelled differently across variants, and raw text lines often combine unrelated numeric and currency characters.
Catalog Mapping and Standardization
A single motorcycle model can be listed as "RE Classic 350" on one portal and "Royal Enfield Classic 350 ABS" on another. KNDUSC’s advanced post-processing pipelines parse these text fields through custom string-matching algorithms, linking diverse marketplace entries back to a single unified master item SKU.
Numeric Extraction and Sanitization
Our data pipelines instantly clean string anomalies—stripping away localized text tags like "Rs.", "Lakh", and "*Onwards". They transform chaotic pricing text fields into clean integers and floats, ready to be fed directly into your internal corporate business intelligence software.
5. Real-World Applications: Who Utilizes Scraped Two-Wheeler Data?
- Auto Manufacturers (OEMs): Track competitor price corrections and new variant launches in real-time to quickly adjust production volumes and plan strategic discount structures.
- Dealership Groups: Monitor localized on-road dealer pricing trends to optimize local walk-in conversion incentives and stay ahead of competing showrooms.
- Fintech & Auto Insurance Providers: Scrape real-world vehicle use metrics and model depreciation matrices to build highly profitable, risk-adjusted insurance premium policies and EMI loan offerings.
6. The KNDUSC Advantage: Fully Managed Automotive Data Pipelines
Building, updating, and maintaining in-house scraping tools to extract data from rapidly changing Single Page Applications is an expensive, continuous drain on internal engineering resources. When automotive platforms update their CSS styling or layout code, traditional internal scrapers break instantly, cutting off critical strategic data feeds.
KNDUSC Innovations eliminates this engineering burden entirely by offering a premium, end-to-end Data-as-a-Service (DaaS) model:
- Detailed System Scoping: We align with your analytics team to map out your exact needed variables, target geographies, and preferred data structure formats.
- Risk-Free Custom Datasets: We construct a custom pipeline prototype and deliver a tailored, high-fidelity sample dataset built to your exact programmatic criteria, entirely free of charge.
- Production Scale Delivery: Once validated, data harvesting scales seamlessly to enterprise volumes. Pristine data is piped directly into your internal infrastructure via custom low-latency APIs, secure cloud storage buckets (AWS S3, Google Cloud Storage), or secure SFTP connections.
7. Conclusion: Seize Your Digital Shelf Advantage
In India's hyper-competitive two-wheeler retail theater, relying on lagging quarterly metrics or slow manual reviews places your business at an immediate competitive disadvantage. Deploying automated web data extraction provides a real-time window into competitor pricing shifts, localized stock movements, and emerging consumer trends.
Stop fighting with proxy blocks, dynamic JavaScript states, and inconsistent data sets. Partner with the data engineering specialists at KNDUSC Innovations to build a dependable, fully automated automotive data pipeline tailored to your enterprise strategic goals.
Ready to harness deep market data? Contact KNDUSC Innovations today. Our lead data engineers will assess your project scope and deliver a comprehensive data blueprint within one business hour.