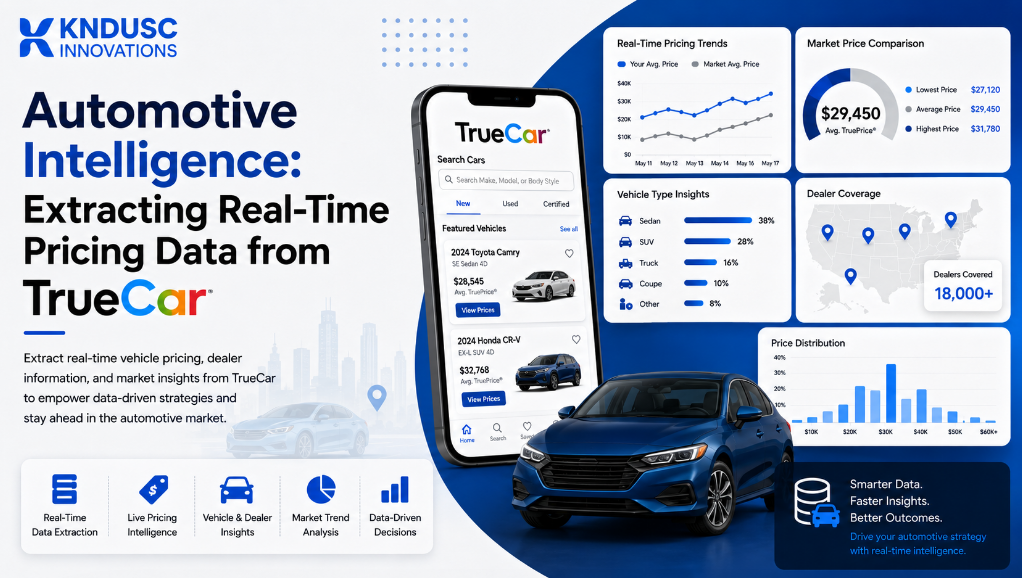
Navigating the automotive retail market requires a deep understanding of localized supply, fluctuating factory incentives, and highly transparent consumer pricing benchmarks. In the digital auto space, few platforms carry as much pricing authority as TrueCar. By aggregating real-time transaction data from thousands of certified dealerships, TrueCar provides a transparent look at what consumers are actually paying for specific vehicles in their local market.
For original equipment manufacturers (OEMs), multi-brand dealership networks, fleet management firms, and auto-fintech lenders, accessing this real-time inventory and pricing loop is a major asset. It allows businesses to optimize wholesale buying strategies, track competitor discounts, and build accurate vehicle depreciation models.
However, capturing this data smoothly means navigating complex web elements and strict network blocks. Below, we look at the specific data layers inside TrueCar and outline how custom automated data solutions convert raw vehicle pages into structured market intelligence.
Uncovering the Unique Layers of TrueCar's Data Ecosystem
Unlike typical e-commerce sites where a product has a static price tag, automotive data is highly fragmented and context-dependent. TrueCar's interface relies on three distinct data layers that must be accurately identified to capture clean intelligence.
1. The Regional Upfront Pricing Certificate
TrueCar's core value proposition is showing the "TruePrice"—an upfront, guaranteed price from a local certified dealer that includes factory incentives and regional discounts. This value shifts dynamically based on the user's selected ZIP code and proximity to available inventory. A standard data harvesting script running on a generic data center server will pull basic national averages that do not reflect true local market incentives. To get accurate visibility, a data pipeline must inject precise regional location parameters into the session logic to capture store-specific quotes.
2. VIN-Level Specification Arrays
Every vehicle listing on TrueCar is anchored by a unique Vehicle Identification Number (VIN). Hidden within the page layout are deep, nested technical specifications—including precise trim packages, added factory options, interior materials, and drivetrain configurations. Naive web scripts often miss these details because they are nested inside complex script containers rather than plain text headings. Properly extracting these attributes allows auto analysts to run true, apple-to-apple market value comparisons.
3. TrueCar Price Rating Indicators
TrueCar algorithmically grades every listing, labeling deals from "Excellent" to "High Price" based on historical local transactions. Capturing these rating markers alongside the vehicle’s list price gives dealerships and remarketing teams a clear look at how the market views specific pricing structures.
Technical Realities: Why Standard Scraping Methods Fail on TrueCar
Building an in-house tool to crawl automotive aggregation sites presents major technical challenges. TrueCar utilizes multi-layered security firewalls to protect its proprietary dealership networks and pricing databases from automated collection.
- Advanced Browser Fingerprinting: TrueCar's edge defenses inspect incoming web traffic well beyond basic request frequency limits. The system reviews deep connection signatures, analyzing TLS handshakes, canvas tracking elements, and WebGL browser traits. If a tool presents an inconsistent or machine-like fingerprint, the firewall drops the connection, leading to endless loops of verification screens or immediate HTTP 403 blocks.
- Dynamic Data Hydration: TrueCar operates on modern frontend frameworks where live inventory counts, dealer discount margins, and calculated financing options load asynchronously via hidden backend client states. Simple scripts that only read the raw HTML source code will pull empty containers. Capturing this data requires advanced headless automation frameworks capable of handling fully rendered browser sessions or safely extracting data from nested JSON payloads.
Transforming Raw Automotive Code into Reliable Business Assets
Extracting text strings from car listings is only the first step. Raw data pulled from web endpoints is naturally noisy—combining unrelated text, local symbols, and varied model names into single lines.
Catalog Alignment and Standardization
Separate dealerships often list identical car models using varied titles (e.g., "2024 Ford F-150 XLT" vs. "F150 SuperCrew XLT 2024"). Automated data processing pipelines must clean and parse these variations, using the VIN code as a primary anchor to link scattered listings back to a single, clean internal master index.
Multi-Market Competitive Benchmarking
To capture a comprehensive view of the automotive landscape, market analytics teams must evaluate data from multiple platforms simultaneously. Our advanced data delivery systems allow your analytical tools to review these insights side-by-side with your existing market maps. For instance, you can cross-reference auction-specific valuations through our Copart Scraper API 2026 pipeline, track deep historical pricing shifts via our Autotrader data extraction guide, or monitor parallel European vehicle trends using our specialized mobile.de data scraping post.
Managed Automotive Data Infrastructure: Zero Internal Maintenance
Continually updating internal web crawlers to manage changing site layouts, hidden API endpoint updates, and proxy network rotations is an expensive, ongoing distraction for your core software developers. The moment an auto platform updates its frontend code or validation headers, home-grown scripts break, leaving your analytics teams with critical data gaps.
At KNDUSC Innovations, we eliminate this technical overhead entirely by offering a premium, end-to-end Data-as-a-Service (DaaS) model.
Our team aligns with your analytics division to map out your exact needed variables, target geographies, and formatting requirements. We then construct a custom processing pipeline and deliver a tailored sample dataset mapped directly to your company's database structure, completely free of charge. Once verified, data harvesting scales seamlessly to production volumes. Clean, structured data is piped directly into your internal workflows via custom api integrations, secure cloud storage options, or direct webhook connections.
Summary: Gain a Clear Market Edge
In a fast-moving automotive retail environment, relying on slow manual audits or outdated historical reports places your business at an immediate disadvantage. Implementing automated web data extraction provides a real-time window into competitor price adjustments, localized inventory movements, and shifting consumer trends.
Stop fighting with proxy errors, browser fingerprint bans, and broken scraping scripts. Partner with the data engineering specialists at KNDUSC Innovations to build a dependable, fully automated data pipeline configured precisely for your company's strategic goals.
Ready to harness deep automotive market intelligence? Contact our strategy team today through our main solutions portal. Our senior data architects will assess your project scope and deliver a comprehensive data blueprint within one business hour.