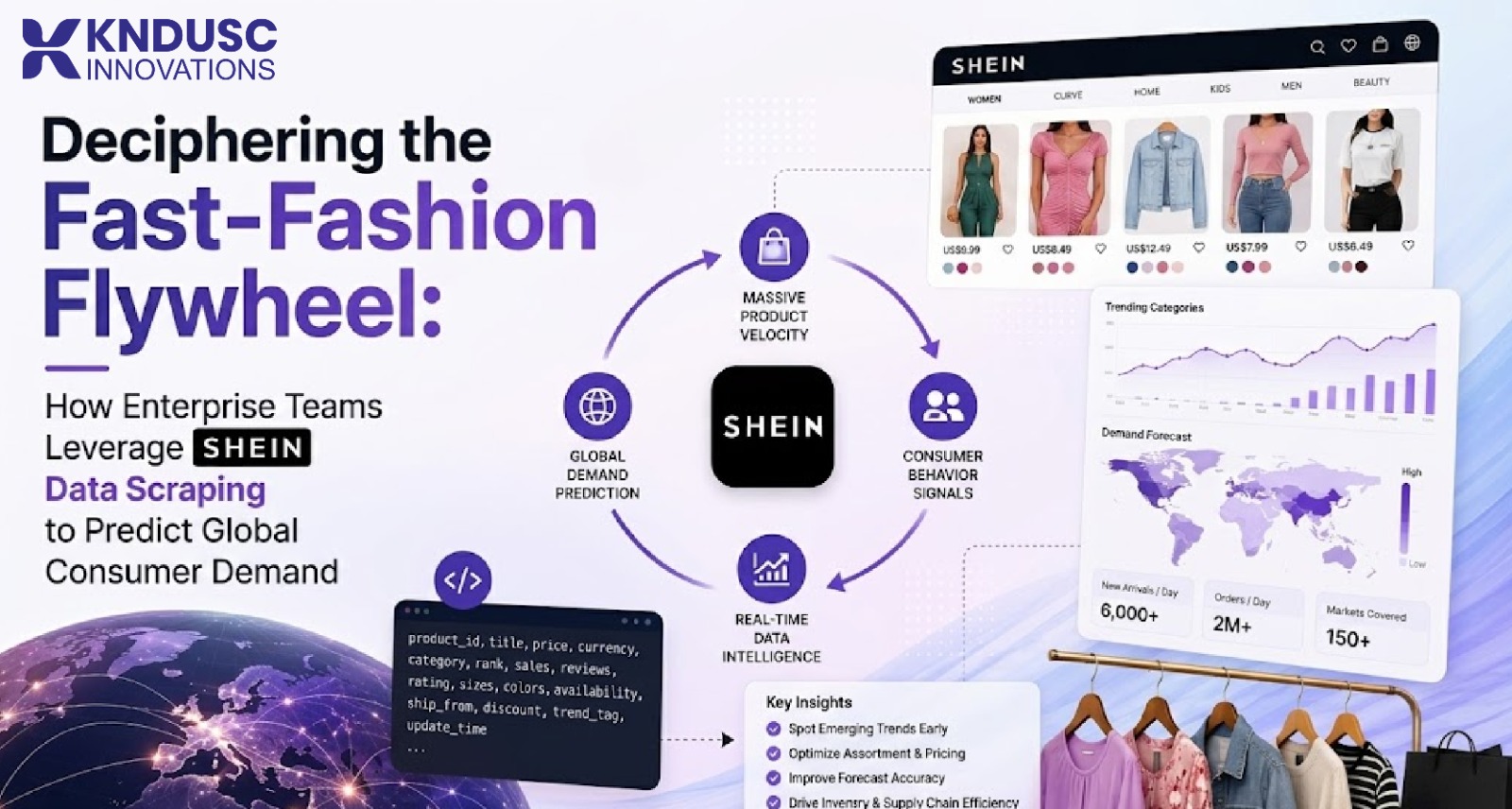
Why has tracking Shein data become vital for traditional retail survival?
Traditional apparel brands operate on months-long manufacturing cycles, whereas Shein relies on an ultra-rapid Consumer-to-Manufacturer (C2M) production loop. By testing thousands of new design variants daily in miniature batches (often just 100 to 200 items) and monitoring instant digital engagement signals (likes, click-through rates, and "add-to-cart" actions), they mass-produce only the items proven to convert.
For competing fashion labels, multi-brand retailers, and hedge funds, executing continuous Shein data scraping is the only reliable method to intercept these digital demand signals early. This allows businesses to adjust their own sourcing, manufacturing, and inventory distribution schedules before consumer trends shift.
How has Shein's recent business expansion altered its data landscape?
Shein is no longer just a standalone budget apparel website; it has evolved into a vast digital mall driven by a hybrid third-party marketplace model. Furthermore, with Shein actively turning its ultra-fast supply chain into a commercial B2B service for external independent brands and acquiring major industry names like Everlane, its data layer now contains highly complex merchant tracking points, layered tiered-pricing matrices, and cross-border logistical variables.
1. Navigating Shein’s Technical Walls: The 51% Success Rate Barrier
Independent industry benchmark tests reveal a striking truth: standard web scrapers trying to access shein.com average a dismal success rate of just over 51%. The platform represents one of the most challenging, block-heavy environments in modern e-commerce.
The JavaScript Hydration Trap
Shein's massive catalog, which expands by tens of thousands of new listings weekly, does not reside cleanly within static HTML files. Instead, pages are rendered dynamically on the client side using heavily obfuscated JavaScript frameworks. Simple, resource-efficient scripts that pull raw HTML code return incomplete elements, entirely missing crucial sizing variants, localized currency values, and live stock tags.
Aggressive Browser Fingerprint Screening
Shein uses advanced web security perimeters that analyze deep network handshakes and browser properties. If a scraping tool exhibits inconsistent TLS handshakes, lacks authentic Canvas or WebGL rendering traits, or moves with mechanical request tempos, the edge firewall instantly blocks the connection. This results in endless loops of complex CAPTCHA challenges or flat HTTP 403 Forbidden responses.
2. Decoding the KNDUSC Solution: High-Throughput Evasion Engineering
Overcoming these strict defenses requires moving away from static scraping setups. At KNDUSC Innovations, we deploy specialized, automated web data frameworks that handle complex enterprise targets smoothly.
[Target: Shein Obfuscated Web Grid]
▲
│ (TLS Blending + Global Residential & Mobile Proxy Routing)
[KNDUSC Adaptive Extraction Engine]
│
▼ (Dynamic JS Rendering & Automated SKU Mapping)
[Pristine Corporate Business Intelligence Payloads]
To maintain an unblocked, high-volume flow of fashion intelligence, our systems leverage three specific technical steps:
- Fully Rendered Headless Automation: We utilize customized instances of headless browser tools like Playwright and Puppeteer, tailored to perfectly mirror genuine human interactions—including non-linear cursor movements, staggered page scrolling, and realistic browsing delays.
- Global Mobile & Residential Proxy Meshes: Standard cloud hosting data center IPs are flagged and dropped by e-commerce edge defenses immediately. We route all extraction requests through an expansive network of real residential and mobile carrier (4G/5G) connections, distributing queries naturally across worldwide consumer locations.
- Dynamic Structural Layout Adherence: Rather than depending on fragile, hardcoded element pathways that break the moment a design changes, our ingestion tools analyze underlying semantic patterns. This keeps your data pipelines working flawlessly even during sudden site layout updates.
3. High-Yield Fashion Attributes to Target for Analysis
To feed predictive trend-forecasting algorithms effectively, an automated data collection pipeline must accurately isolate and structure several core data fields:
| Target Ingestion Layer | Specific Data Attributes | Strategic Analytical Value |
|---|---|---|
| Catalog Metadata | Product Title, Brand Source, Multi-Tier Category Hierarchies, Unique SKU, Material Ratios | Powers automated catalog classification and tracks fast-moving trend categories. |
| Pricing Variables | Base Retail Price, Multi-Buy Discount Breaks, In-App Points Multipliers, Flash Coupon Triggers | Fuels automated dynamic repricing models and maps competitor discount strategies. |
| Logistics & Inventory | Initial Batch Indicators, Localized Out-of-Stock Flags, Regional Warehouse Groupings | Measures production velocity and uncovers localized demand spikes. |
| Social Validation | Cumulative Review Tallies, Image Upload Counts, Verified Purchase Indicators | Tracks localized consumer reception and flags unexpected product flaws. |
4. Normalizing the Fast-Fashion Stream Into Actionable Metrics
Raw strings harvested from deep e-commerce scraping operations are notoriously chaotic. Text strings combine unrelated size details, mixed regional symbols, and unformatted descriptions into single lines.
Cross-Market Catalog Mapping
A single style variant may be marketed under slightly altered titles across distinct regional domains. KNDUSC’s data cleansing pipelines run these raw inputs through custom string-matching algorithms, linking diverse marketplace options back to unified, master item SKUs.
Contextual Cross-Platform Benchmarking
To capture a truly accurate view of the fashion and consumer retail landscape, enterprise teams must cross-examine multi-platform datasets simultaneously. Our scalable data streams allow your business intelligence applications to analyze Shein analytics side-by-side with other critical marketplace channels. This lets you contrast fast-fashion trends against high-end apparel catalogs by integrating Myntra data scraping API pipelines, monitoring parallel digital shelf allocations through our specialized Ajio data scraping services, or checking mass marketplace trends via our comprehensive Amazon data scraping and API infrastructure.
5. Fully Managed Data Infrastructure: Eliminating Technical Overhead
Continually building and maintaining internal web scrapers to navigate deep JavaScript structures and handle complex proxy configurations is an expensive, ongoing distraction for your core engineering teams. When marketplace layouts alter their front-end source code, home-grown scripts break instantly, leaving strategic analytics platforms with critical data blackouts.
KNDUSC Innovations eliminates this resource drain entirely by providing a premium, end-to-end Data-as-a-Service (DaaS) model:
- Comprehensive Property Mapping: We align with your technical team to map out your target variables, desired geographic tracking coordinates, and required final formats.
- Risk-Free Schema Prototyping: We build a custom processing prototype and deliver a tailored, high-fidelity sample dataset configured exactly to your internal database parameters, completely free of charge.
- Production Scale Delivery: Once validated, data collection scales seamlessly to enterprise volumes. Pristine data is piped directly into your internal workflows via custom api integrations, secure cloud storage buckets (AWS S3, Google Cloud Storage), or secure SFTP connections.
6. Conclusion: Capitalize on Real-Time Trend Intelligence
In the ultra-fast global apparel sector, relying on lagging market reports or manual checks places your organization at an immediate competitive disadvantage. Deploying automated web data extraction provides a real-time window into competitor pricing shifts, localized stock movements, and emerging consumer purchasing habits.
Stop battling with proxy blocks, browser fingerprints, and broken collection scripts. Partner with the data engineering specialists at KNDUSC Innovations to build a dependable, fully automated data pipeline configured precisely for your company's strategic goals.
Ready to harness deep fast-fashion data? Contact our strategy team today through our main solutions portal. Our senior data architects will assess your project scope and deliver a comprehensive data blueprint within one business hour.